全面解读CAP定理
2000年的时候,加州大学伯克利分校的光头教授Eric Brewer提出了CAP猜想:CAP永远不可能同时满足,提高其中任意两者的同时,必然要牺牲第三者。这个定理告诉大家,不要再浪费时间去研究如何兼顾了,因为这根本就是不可能的,只能根据具体应用,来决定如何在三者之间进行取舍。

后来,CAP猜想由麻省理工学院的两位科学家证明。CAP猜想的证明相对比较简单:采用反证法,如果三者可同时满足,则因为允许P的存在,一定存在节点之间的丢包,如此则不能保证C,证明简洁而严谨。从此,CAP理论正式在学术上成为了分布式计算领域的公认定理,并深深的影响了分布式计算的发展。
但是,在CAP理论提出十二年之后,Eric Brewer教授又出来辟谣:“三选二”的公式一直存在着误导性,它会过分简单化各性质之间的相互关系。这三种性质都可以在某种程度上进行衡量,并不是非黑即白的有或无。可用性显然是在0%到100%之间连续变化的,一致性分很多级别,连分区也可以细分为不同含义,如系统内的不同部分对于是否存在分区可以有不一样的认知。所以,一致性和可用性并不是水火不容,非此即彼的。
| 《全面解读CAP定理》 |
|---|
| 第一节:什么是 CAP 定理? |
| 第二节:什么是分区?什么是分区容错性? |
| 第三节:为什么只能 3 选 2? |
| 第四节:真实的CP场景:GitHub事故:断网43秒,瘫痪24小时 |
| 第五节:CAP理论的新理解 |
第一节:什么是 CAP 定理?
2000 年的时候,Eric Brewer 教授提出了CAP猜想,2年后,被 Seth Gilbert和 Nancy Lynch从理论上证明了猜想的可能性,从此,CAP定理正式在学术上成为了分布式计算领域的公认定理,并深深的影响了分布式计算的发展。
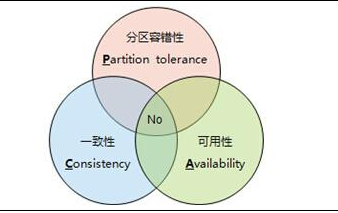
CAP定理,又称CAP原则,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 定理指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
CAP定理的精髓就是要么AP,要么CP,要么AC,但是不存在CAP。因此在进行分布式架构设计时,必须做出取舍。而由于网络硬件肯定会出现延迟丢包等问题,所以分区容错性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡,没有任何分布式系统能同时保证这三点。
| 选项 | 描述 |
|---|---|
| C(Consistence) | 一致性,指数据在多个副本之间能够保持一致的特性(严格的一致性)。 |
| A(Availability) | 可用性,指系统提供的服务必须一直处于可用的状态,每次请求都能获取到正确的响应,但是不保证获取的数据为最新数据。 |
| P(Partition tolerance) | 分区容错性,分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障。 |
第二节:什么是分区?什么是分区容错性?
在分布式系统中,不同的节点分布在不同的子网络中,由于一些特殊的原因,这些子节点之间出现了网络不通的状态,但他们的内部子网络是正常的。从而导致了整个系统的环境被切分成了若干个孤立的区域,这就是分区。
分区容错性,说白了,就是指是否允许出现分区。一旦出现分区,则各个分区之间的数据副本无法达到一致性。
第三节:为什么只能 3 选 2?
假设有一个系统如下:
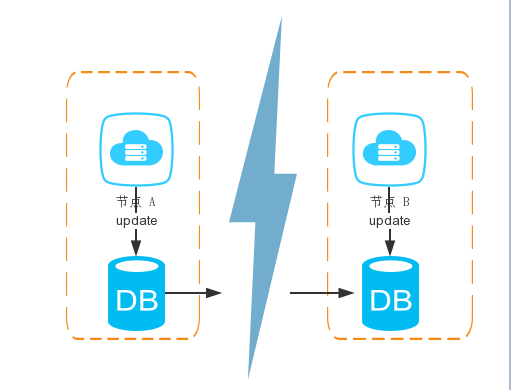
整个系统由两个节点配合组成,节点之间通过网络通信,当节点 A 进行更新数据库操作的时候,需要同时更新节点 B 的数据库(满足一致性)。这个系统怎么满足 CAP 呢?
C:当节点A更新的时候,节点B也要更新;
A:必须保证两个节点都是可用的;
P:当节点 A,B 出现了网络分区,必须保证对外可用。
可见,三者根本无法同时满足,只要出现了网络分区,一致性就无法满足,因为节点 A 根本连接不上节点 B。如果强行满足一致性,就必须停止服务运行,从而放弃可用性 。所以,最多满足两个条件,并有下面几种情况:
| 组 合 | 分析 |
|---|---|
| CA | 满足一致性和可用,放弃分区容错。此时已经变成了单机系统,谈不上是分布式系统了。对于分布式系统而言,分区容错性是一个最基本的要求,因为分布式系统中的组件必然需要部署到不通的节点,必然会出现子网络,在分布式系统中,网络问题是必定会出现的异常。因此分布式系统只能在C(一致性)和A(可用性)之间进行权衡。 放弃分区容错性,比较简单的方式就是把所有的数据都放在一个分布式节点上。那不就又成为了单机应用了吗? |
| CP | 满足一致性和分区容错,也就是说,要放弃可用。当系统被分区,为了保证一致性,必须放弃可用性,让服务停用。 放弃可用性,一旦出现网络故障,受到影响的服务需要再等待一定时间,因为系统处于不可用的状态。 |
| AP | 满足可用性和分区容错,当出现分区,同时为了保证可用性,必须让节点继续对外服务,这样必然导致失去一致性。 放弃一致性,这里所指的一致性是强一致性,但是确保最终一致性。是很多分布式系统的选择。 |
第四节:真实的CP场景:GitHub事故:断网43秒,瘫痪24小时
2018年10月31日,GitHub技术负责人Jason Warner的一篇技术深度解析稿成为IT圈爆款。文中,Jason坦诚地对外讲述了10月21日100G光缆设备故障后,Github服务降级的应急过程以及反思总结。
从Jason Warner的文章中不难看出,造成断网43秒瘫痪24小时的罪魁祸首是数据库。由于部署在两个数据中心的数据库集群没有实时同步。意外发生时,Github的工程师担心数据丢失,不敢快速将主数据库安全切换到东海岸的备份数据中心。
程序员们在GitHub这篇“忏悔录”下面留言,表达对数据库集群的“哀悼”。但更多IT从业者关心的问题是,如何避免这样的灾难事件降临到自己的公司,自己维护的系统。
分布式数据库专家认为,此次Github事件是典型的城市级故障。如果系统采用的是高可用的三地五中心解决方案,就可以自如应对。
原来,Github类似银行采用的传统数据库两地三中心模式,即“主库(主机房)+同城热备库(同城热备机房)+异地灾备库(异地灾备机房)”。这种方式下通常只有主机房的服务器能提供写服务。如果主城市出现城市级故障,灾备城市的数据库虽然可以工作,但由于没有同步的最新数据,因此灾备库的数据是有损的。Github表示,为了保证数据完整性,他们不得不牺牲恢复时间。
其实,这个问题采用三地五中心方案可以更好的应对。城市故障时,只要活着的两个城市的三个机房两两之间能够通信,就可以正常服务,也不会有任何的数据损失。
第五节:CAP理论的新理解
有读者存在疑问:根据CAP理论,在分布式系统中一致性和可用性只能选一个,那Paxos、Raft等共识算法是如何做到在保证一定的可用性的同时,对外提供强一致性呢?
这个疑问的根源在于没有明白CAP理论后期的发展。在CAP理论提出十二年之后,其作者又出来辟谣:“三选二”的公式一直存在着误导性,它会过分简单化各性质之间的相互关系。
首先,由于分区很少发生,那么在系统不存在分区的情况下没什么理由牺牲C或A。
其次,C与A之间的取舍可以在同一系统内以非常细小的粒度反复发生,而每一次的决策可能因为具体的操作,乃至因为牵涉到特定的数据或用户而有所不同。
最后,这三种性质都可以在程度上衡量,并不是非黑即白的有或无。可用性显然是在0%到100%之间连续变化的,一致性分很多级别,连分区也可以细分为不同含义,如系统内的不同部分对于是否存在分区可以有不一样的认知。所以,一致性和可用性并不是水火不容,非此即彼的。