在线强化学习与离线强化学习
强化学习分为两大类:online RL(在线强化学习) 和 offline RL(离线强化学习)
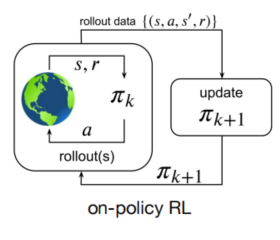
在线强化学习
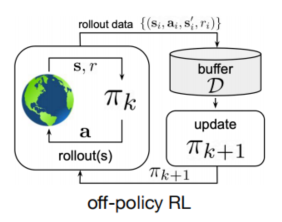
学习过程中,智能体需要和环境进行交互。并且,在线强化学习又可分为on-policy RL和off-policy RL。on-policy采用的是当前策略搜集的数据训练模型,每条数据仅使用一次。off-policy训练采用的数据不需要是当前策略搜集的。on-policy RL算法有:REINFORCE、A3C、PPO 等,而off-policy RL算法有:Q-learning、DQN、DDPG、SAC 等。
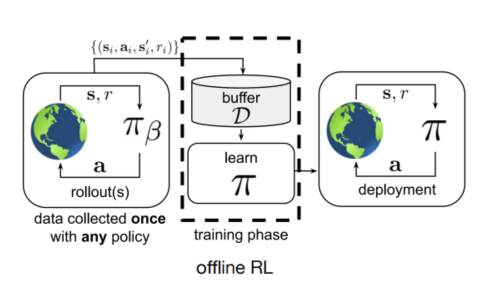
离线强化学习
学习过程中,不与环境进行交互,只从dataset中直接学习,而dataset是采用别的策略收集的数据,并且采集数据的策略并不是近似最优策略。
$P\left(x_{t+1} \mid x_{t}, x_{t-1}, \ldots, x_{1}\right)=P\left(x_{t+1} \mid x_{t}\right)$