Redis的进化之路:从单线程到多线程的升级
前言
本文的内容来源于互联网,可谓是博采众家之长,并稍微添加了一些我的个人经验。说实话,我并没有阅读过Redis的源码,但是我之前花费了很多时间用Linux的Epoll开发Socket项目,所以对Redis高并发所依仗的I/O复用机制有深刻的感悟,绝非纸上谈兵。
看到很多人在分享I/O复用机制的相关内容,我的忠告是,对于一个纯Java的博主说,不管你的构图做的多么精美,多么用心,但是如果你没有真正的使用过C++与Epoll,你只不过是在给读者画饼,给读者空谈而已。
很多人没有掌握高并发,根本原因在于:掌握高并发不是看看网、读读书就能掌握的,你必须真正的使用C++和Epoll做过项目。此时,这个问题就更复杂了,你一个搞Java的人,怎么还要去学习C++呢?这个问题我也无法回答,我只知道:仅仅学习Java的人,永远成为不了高手。当然,我并不是要号召大家学习Java,我只是在说明一个道理,这个道理就是:只有真正使用过C++和Epoll的人才能掌握高并发。
好了,言归正传,继续本文的主题:Redis的进化史。
单线程的Redis
在Redis 4.0版本之前是单线程的。提到单线程,很多人脑海中会蹦出“低效”的意识。其实,很多人对多线程抱有误解,最终导致对单线程造成偏见。要想纠正这种偏见,必须追根溯源,对多线程进行“拨乱反正”:多线程不是为了提高运行效率,而是为了提高资源使用效率,从而最终提高系统的整体效率。
对于Redis而言,由于它主要是内存操作,资源利用率已经很高了,所以没有必要再使用多线程了。之所以使用单线程的运行模式Redis还是非常快、吞吐量非常大,根本原因在于以下几点:
- 基于内存操作:Redis的所有数据都在内存中,因此所有的运算都是内存级别的,所以它的性能比较高
- 数据结构简单:Redis的数据结构是为自身专门量身打造的,而这些数据结构的查找和操作的时间复杂度都是O(1)
- 多路复用和非阻塞I/O:Redis使用I/O多路复用功能来监听多个客户端socket连接,这样就可以使用一个线程来处理多个请求的情况,从而减少线程切换带来的开销,同时也避免了I/O阻塞操作,从而大大地提高了Redis的性能。
- 避免上下文切换:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,也就省去了多线程切换带来的时间和性能上的开销。
Redis能做到高性能,很大程度上依靠的是非阻塞I/O和I/O多路复用,这又是什么高科技呢?请看下文的介绍:
首先我们可以使用 get 命令,获取一个 key 对应的 value,比如:
127.0.0.1:6379> get name
"Tom"那么问题来了,以上对于 Redis 服务端而言,都发生了哪些事情呢?
Redis服务端必须要先监听客户端请求(bind/listen),此时建立监听socket,然后当客户端到来时与其建立连接(accept),此时再建立连接socket,随后从该socket中读取客户端的请求(recv),并对请求进行解析(parse),这里解析出的请求类型是get,key是"name",再根据key获取对应value,最后返回给客户端,也就是向连接socket写入数据(send)。
以上所有操作都是由Redis主线程依次执行的,但是里面会有潜在的阻塞点,分别是accept和recv。当 Redis监听到一个客户端有连接请求,但却一直未能成功建立连接,那么主线程会一直阻塞在accept函数这里,导致其它客户端无法和Redis建立连接。类似的,当Redis通过recv函数从客户端读取数据时,如果数据一直没有到达,那么Redis主线程也会一直阻塞在recv这一步,因此这就导致了Redis的效率会变得低下。
实际上,Redis不会允许这种情况发生,因为以上都是阻塞I/O会面临的情况,而Redis采用的是非阻塞I/O,也就是将监听socket设置成了非阻塞模式。如果没有客户端连接请求到达时,那么主线程就不会傻傻地等待了,而是会直接返回,然后去做其它的事情。类似的,我们在创建连接socket的时候也可以将其类型设置为非阻塞,那么当调用 recv() 但却收不到数据时,也不用处于阻塞状态,同样可以直接返回去做其它事情。
虽然accept()不阻塞了,在没有客户端连接时Redis主线程可以去做其它事情,但如果后续有客户端连接,Redis要如何得知呢?因此必须要有一种机制,能够在请求到来时通知 Redis。这种机制便是 I/O 多路复用。
I/O 多路复用机制是指一个线程处理多个IO流,也就是我们经常听到的 select/poll/epoll,而Linux采用的是epoll。简单来说,在Redis只运行单线程的情况下,该机制允许内核中同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求,一旦有请求到达就会交给 Redis 线程处理,这样就实现了一个Redis线程处理多个IO流的效果。
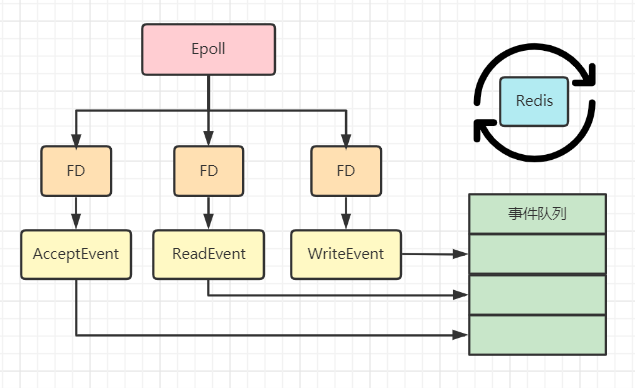
上图就是基于多路复用的 Redis IO 模型,图中的 FD 就是套接字,Redis 会通过 Epoll 机制来让内核帮忙监听这些套接字。而此时 Redis 主线程并不会阻塞在某一个特定的套接字上,也就是说不会阻塞在某一个特定的客户端请求处理上。因此 Redis 可以同时和多个客户端连接并处理请求,从而提升并发性。但为了在请求到达时能够通知 Redis 线程,Epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。那么回调机制是怎么工作的呢?以上图为例,首先 Epoll 一旦监测到 FD 上有请求到达时,就会触发相应的事件。这些事件会被放进一个队列中,Redis 主线程会对该事件队列不断进行处理,这样一来 Redis 就无需一直轮询是否有请求发生,从而避免资源的浪费。同时,Redis 在对事件队列中的事件进行处理时,会调用相应的处理函数,这就实现了基于事件的回调。因为 Redis 一直在对事件队列进行处理,所以能及时响应客户端请求,提升 Redis 的响应性能。
多线程的Redis
Redis 6.0中的多线程则是真正为了提高I/O的读写性能而引入的,它的主要实现思路是将主线程的I/O读写任务拆分给一组独立的子线程去执行,也就是说从socket中读数据和向socket写数据不再由主线程负责,而是交给了多个子线程,这样就可以使多个socket的读写并行化了。这么做的原因就在于,虽然在Redis中使用了I/O多路复用和非阻塞I/O,但是我们知道数据在内核态空间和用户态空间之间的拷贝是无法避免的,而数据的拷贝这一步是阻塞的,并且当数据量越大时拷贝所需要的时间就越多。所以 Redis在6.0引入了多线程,用于分摊同步读写I/O压力,从而提升Redis的QPS。但是注意:Redis的命令本身依旧是由Redis主线程串行执行的,只不过具体的读写操作交给独立的子线程去执行了,而这么做的好处就是不需要为Lua脚本、事务的原子性而额外开发多线程互斥机制,这样一来Redis的线程模型实现起来就简单多了。因为和之前一样,所有的命令依旧是由主线程串行执行的,只不过具体的读写任务交给了子线程。
下面详细介绍一下Redis 6.0的主线程和子线程之间是如何协同的,整体可以分为四个阶段:
第一阶段:服务端和客户端建立socket连接,并分配子线程(处理线程)
首先,主线程负责接收建立连接请求,当有客户端请求到达时,主线程会创建和客户端的 scoket 连接,该 socket 连接就是用来和客户端进行数据的传输的。只不过这一步不由主线程来做,主线程要做的事情是将该 socket 放入到全局等待队列中,然后通过轮训的方式选择子线程,并将队列中的 socket 连接分配给它,所以无论是从客户端读数据还是向客户端写数据,都由子线程来做。因为我们说 Redis 6.0 中引入多线程就是为了缓解主线程的 I/O 读写压力,而 I/O 读写这一步是阻塞的,所以应该交给子线程并行操作。
第二阶段:子线程读取并解析请求
主线程一旦把 socket 连接分配给子线程,那么会进行阻塞状态,等待子线程完成客户端请求的读取和解析,得到具体的命令操作。由于可以有多个子线程,所以这个操作很快就能完成。
第三阶段:主线程执行命令操作
等到子线程读取到客户端请求并解析完毕之后,然后再由主线程以单线程的方式执行命令操作,I/O 读写虽然交给了子线程,但是命令本身还是由 Redis 主线程执行的。
第四阶段:子线程回写socket,主线程清空全局队列
当主线程执行完命令操作时,还需要将结果返回给客户端,而这一步显然要由子线程来做,因为是I/O读写。此时主线程会陷入阻塞,直到子线程将这些结果写回socket并返回给客户端。和读取一样,子线程将数据写回socket时,也是有多个线程在并行执行,所以写回socket的速度也很快。之后主线程会清空全局队列,等待客户端的后续请求。
后记:对于Java程序员来说,是否深刻的理解和掌握高并发是平庸和优秀的分水岭,但是高并发掌握的前提是C、C++/Epoll,学习成本是非常大的。我个人认为没有真正使用过Epoll的人是不可掌握高并发的,所以在站长收徒的传授内容中有专门的Epoll程序动手练习模块,欢迎大家关注。